Anthropic recently published how it runs self-service analytics on Claude. One result caught my eye: context + skills took its analytics agent from 21% accuracy to consistently above 95%.
Highlighting that generating SQL is the easy part, the hard part is everything underneath it: canonical datasets, a semantic layer, lineage, maintained skills, and provenance on every answer.
That jump came from the foundation, not a bigger model. With the context right, the agent on top matters much less.
Why Agents Alone Fail
In addition to cost, three context problems keep coming up.
Entity ambiguity. "Active users" or "revenue" has several definitions in the warehouse. The agent picks one and writes correct SQL against the wrong data.
Staleness. The definition was right when written. Then the pipeline changed and the skill was never updated.
Retrieval failure. The right definition exists somewhere, but the agent can't find it, or grabs the wrong version.
Two of these, staleness and retrieval, can't be fixed easily by prompting alone. They need the context to be a versioned, owned asset wired to the pipeline it describes.
Anthropic tried the shortcut of handing the agent the raw query corpus, and accuracy barely moved. As they put it: "The information was there, the agent saw it, and it still didn't use it."
Skills Are Data Assets
A skill is markdown the agent reads on demand: which dataset is canonical, how a metric is defined, when a number misleads.
But a skill is more than a prompt. It needs an owner, a version, review, and tests against real questions, like any other production data asset.
Anthropic enforces part of that. Skills live in version control next to the data models, and a CI hook forces a skill update whenever the model changes.
Every query also runs through a governed semantic layer first, so the agent can't wander the warehouse and grab whatever field looks right.
We built Belvedere around the same principles. We attach those instructions to the data assets they depend on: the datasets, the contracts (the schema and rules each table promises), and the validation.
Change a dataset or a definition, and Belvedere surfaces the skills, contracts, and pipelines it touches, then routes it through review.
Belvedere uses agents to build the pipeline, not to be the pipeline. They propose the pipelines at design time, a human signs off, and production runs deterministic, owned code.
What Belvedere Manages
Data Discovery: catalogs the data estate you have.
Pipelines: turns plain-English needs into reviewable pipelines and contracts.
Data Changes: keeps definitions, skills, and lineage current as sources change.
Monitoring: watches the pipelines in production and flags drift for review.
Approval: keeps a human in the loop, so nothing ships without sign-off (unless you want it to).
It runs alongside your warehouse, BI tools, and catalog. No rip and replace.
Why Not a Chat Box?
Data is not software, as Anthropic puts it. An analytics question has one correct answer, so you want determinism in the production path, not creativity.
A chat box can write SQL too. But it runs the model again on every question, keeps no inspectable lineage, and can't be re-run the same way twice.
That's fine for exploration, but not for a finance or compliance team that has to stand behind the number.
So Belvedere ships deterministic pipelines instead. A compiled pipeline costs almost nothing to re-run, it's versioned and auditable, and it carries provenance on every result.
What It Looks Like in Belvedere
Take a question every e-commerce team argues about: "What was the true performance of our Q4 holiday campaign across every channel, including returns and refunds?"
Now how would we build this out in Belvedere?
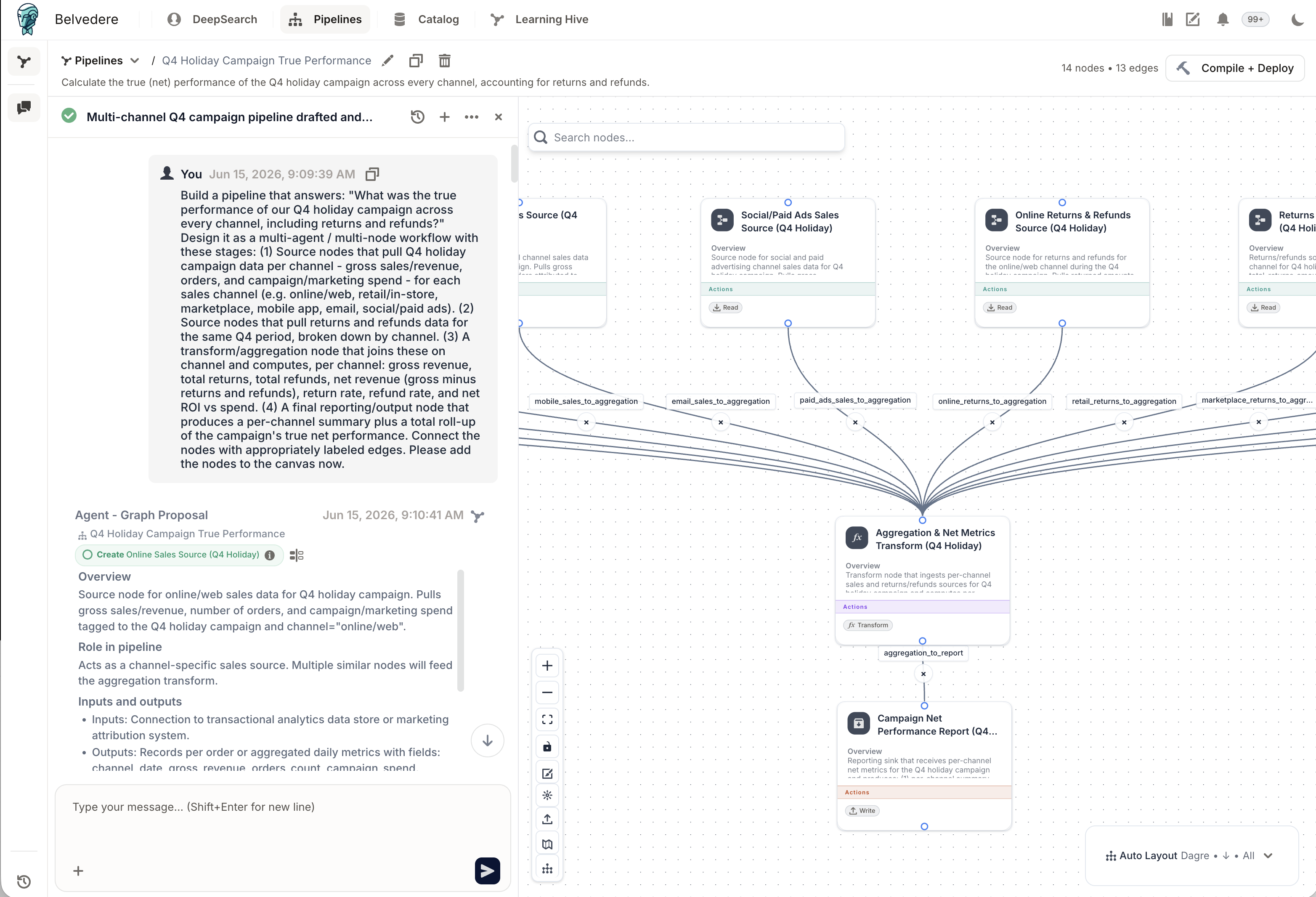
Belvedere proposes the pipeline; nothing runs until you approve it.
Connect your sources: Shopify, Meta, Google, Klaviyo, Google Analytics. Belvedere discovers, catalogs, and enriches them.
Describe what you need in plain English, and Belvedere proposes the pipeline. Where there's a real modeling choice (attribution, say, where last-touch and multi-touch disagree), it won't pick silently; it proposes an approach, asks you to confirm, and records the choice in provenance.
Approve. Nothing runs without your sign-off. Then Belvedere compiles it into a deterministic workflow and tracks lineage.
Maintain. Add a channel or redefine "net revenue," and Belvedere shows what the change touches (contracts, pipelines, downstream tables) and routes it through the same review.
You Don't Have to Build It Yourself
Governed context works. Anthropic proved it, with a setup built by a team that could afford to build it from scratch with a narrow focus on business ops.
You don't need to fund a multi-year internal data-platform project that breaks when a new use case arises.
We can show you how it works on your own data. Book a demo or reach out at info@clearfracture.ai.
Clear Fracture is a startup building Belvedere, an agentic data engineering platform that uses agents to build governed, deterministic pipelines, not to be the pipeline.